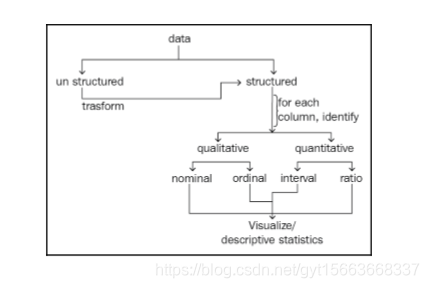
特征理解,简单说就是理解数据中都有什么,对数据的理解方便我们认清数据,从而对数据进行操作,构造有用的特征。我们将从以下几个方面来认清数据:
- 结构化数据与非结构化数据
- 定量数据与定性数据
- 数据的4个等级
- 探索性数据分析和数据可视化
- 描述性统计
1. 结构化数据和非结构化数据
结构化(有组织)数据:分成观察值和特征的数据,以表格的形式组织,行是观察值,列是特征。例如,科学仪器报告的气象数据,是存在表格的行列结构。

非结构化(无组织)数据:作为自由流动的实体,不遵循标准组织结构的数据。例如,服务器日志和推文。
2. 定量数据和定性数据
定量数据:本质上是数值,应该是衡量某样东西的数量。
定性数据:本质上是类别,应该是描述某样东西的性质。
我们首先导入一个数据,这个数据是旧金山做不同工作的工资。
# 导包
# 数学计算包
import numpy as np
# 存储表格数据
import pandas as pd
# 数据可视化包
import matplotlib.pyplot as plt
import seaborn as sns
# 允许行内渲染图形
%matplotlib inline
# 流行的数据可视化主题
plt.style.use('fivethirtyeight')
# 导入数据
salary_ranges = pd.read_csv('./data/Salary_Ranges_by_Job_Classification.csv')
# 查看前几行
salary_ranges.head()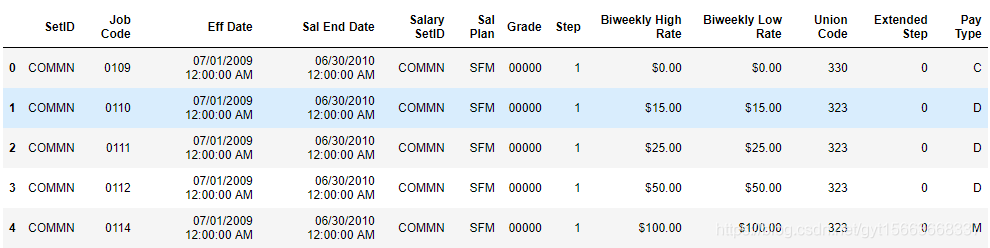
# 查看数据的信息
salary_ranges.info()
# 查看数据是否存在缺失
salary_ranges.isnull().sum()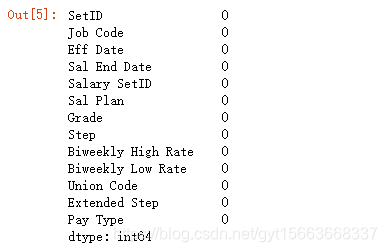
# 数据的描述性统计
salary_ranges.describe()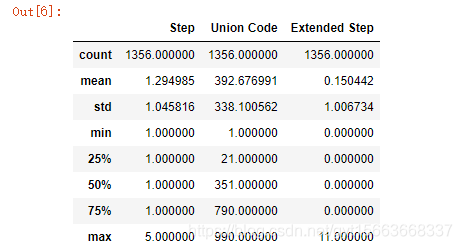
3. 数据的4个等级
每个等级都有不同的控制和数学操作等级。了解数据让我们选择合适的可视化类型和操作。
(1)定类等级
定类等级,其结构最弱。数据只按名称分类。例如血型和人名。这些数据都是定性的。定类等级的数据上不能执行任何定量的数学操作。如下,对工作种类进行计数,出现次数最多的工作种类是00000。
# 对工作种类进行计数
salary_ranges['Grade'].value_counts().head()
# 对工作种类绘制条形图
salary_ranges['Grade'].value_counts().sort_values(ascending=False).head(20).plot(kind='bar')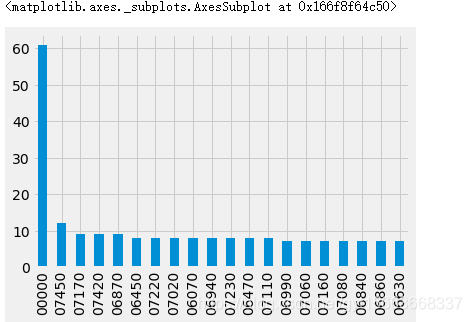
# 绘制饼图
salary_ranges['Grade'].value_counts().sort_values(ascending=False).head(5).plot(kind='pie')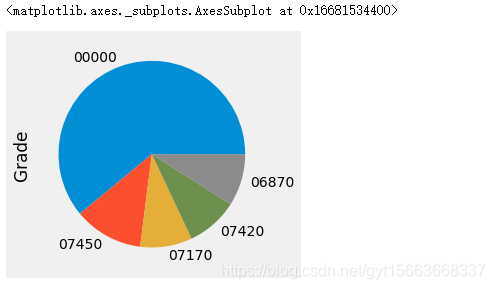
(2)定序等级
定序等级继承了定类等级的属性,而且有重要的附加属性。定序等级的数据可以自然排序,但其天然数据属性仍然是类别。定序等级数据也是定性的。其可以像定类等级一样计数,还可以;引入比较和排序。还可以绘制茎叶图和箱线图。例如考试的等级(F、D、C、B、A)。我们使用旧金山国际机场的数据来实现操作。在这个数据的Q7A_ART属性是关于;艺术品和展览的,能选择的是0,1,2,3,4,5,6,每个数字都有含义。我们只考虑1-5。
# 导入数据集
customer = pd.read_csv('./data/2013_SFO_Customer_survey.csv')
customer.shape
# 只考虑1-5
art_ratings = art_ratings[(art_ratings >= 1) & (art_ratings <= 6)]
# 将值转为字符串
art_ratings = art_ratings.astype(str)
art_ratings.describe()
# 使用条形图进行可视化
art_ratings.value_counts().plot(kind='bar')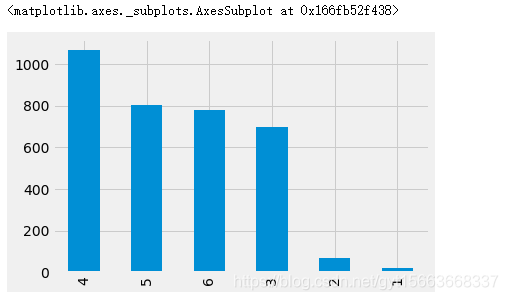
# 使用箱线图进行可视化
art_ratings.value_counts().plot(kind='box')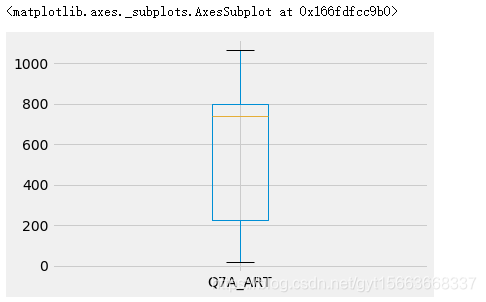
(3)定距等级
定距等级的数据是定量的数据。定距等级的数据之差是有意的。因此,不仅可以对值进行排序和比较,还可以进行加减法的运算。例如,当我们考虑温度的时候,上海的温度是32度,哈尔滨的温度是4度,32-4=28代表两地的温差为28度。相反,对于李克特量表做这种减法则没有任何意义。
# 加载数据
climate = pd.read_csv('./data/GlobalLandTemperaturesByCity.csv')
# 移除缺失值
climate.dropna(axis=0, inplace=True)
climate.head()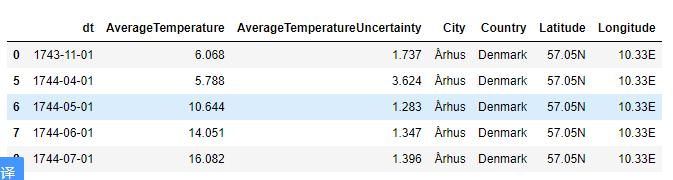
# 对温度画直方图,擦好看温度分布
climate['AverageTemperature'].hist()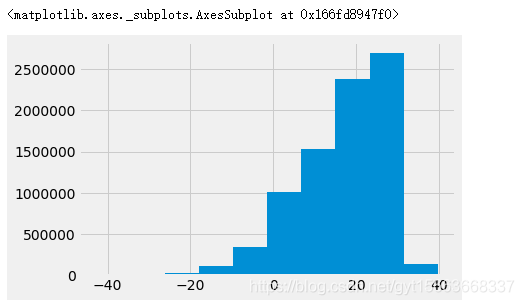
# 将dt栏转换为日期,取年份
climate['dt'] = pd.to_datetime(climate['dt'])
climate['year'] = climate['dt'].map(lambda value: value.year)
# 只看美国
climate_sub_us = climate.loc[climate['Country'] == 'United States']
climate_sub_us['century'] = climate_sub_us['year'].map(lambda x: int(x/100+1))
# 使用新的centery列,对每个世纪化直方图
climate_sub_us['AverageTemperature'].hist(by=climate_sub_us['century'], sharex=True, sharey=True, figsize=(10, 10), bins=20)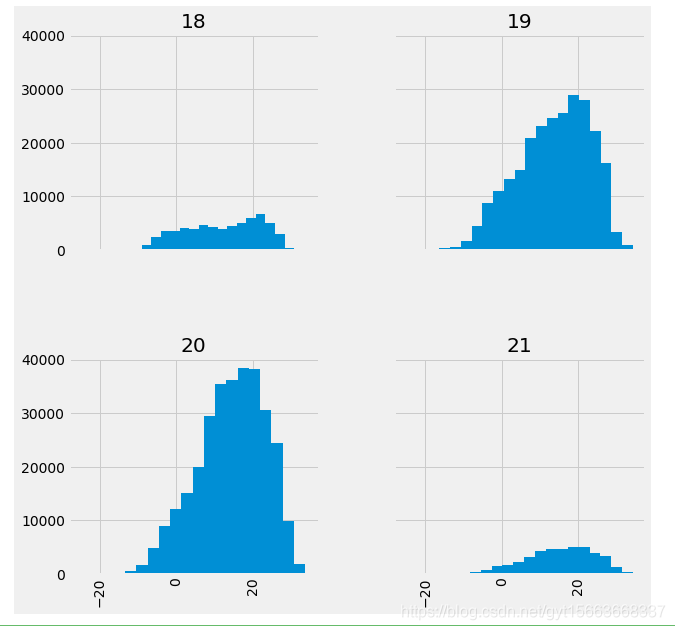
climate_sub_us.groupby('century')['AverageTemperature'].mean().plot(kind='line')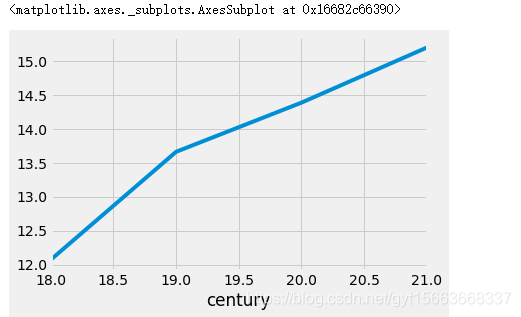
在气候变化数据集中,我们针对year和averageTemperature两列数据进行描绘。
x = climate_sub_us['year']
y = climate_sub_us['AverageTemperature']
fig, ax = plt.subplots(figsize=(10, 5))
ax.scatter(x, y)
plt.show()
# 用groupby清除美国气温的噪声
climate_sub_us.groupby('year').mean()['AverageTemperature'].plot()
# 用滑动均值平滑图像
climate_sub_us.groupby('year').mean()['AverageTemperature'].rolling(10).mean().plot()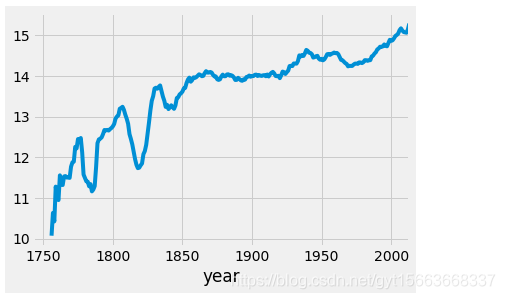
(4)定比等级
定比等级处理的也是定量数据,拥有最高程度的控制和数学运算能力。除了加减运算,还有一个绝对零点的概念,可以做乘除运算。例如,100元是50元的两倍。$100/50=2$。
# 那个工资最高
fig = plt.figure(figsize=(15, 5))
ax = fig.gca()
salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False).head(20).plot.bar(stacked=False, ax=ax, color='darkorange')
ax.set_title('Top 20 Grade by Mean Biweekly High Rate')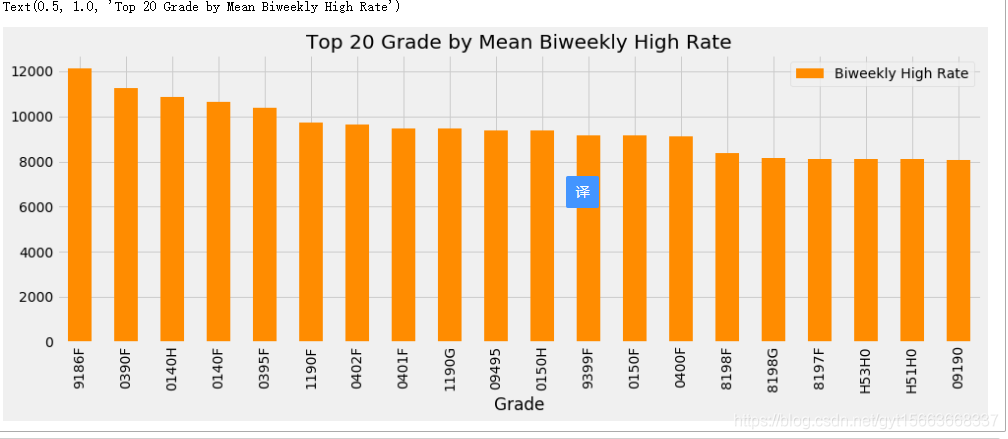
# 哪个工作工资最低
fig = plt.figure(figsize=(15, 5))
ax = fig.gca()
salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False).tail(20).plot.bar(stacked=False, ax=ax, color='darkorange')
ax.set_title('Bottom 20 Grade by Mean Biweekly High Rate')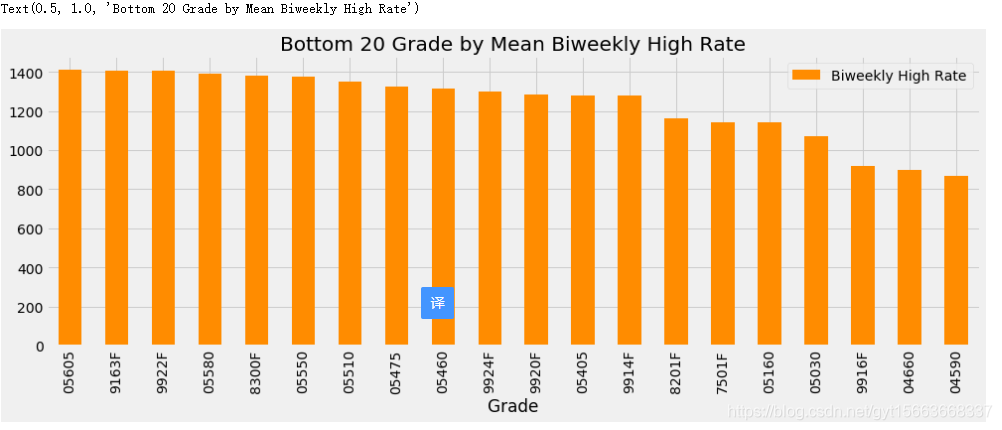
# 计算最高工资和最低工资的比值
sorted_df = salary_ranges.groupby('Grade')[['Biweekly High Rate']].mean().sort_values('Biweekly High Rate', ascending=False)
sorted_df.iloc[0][0] / sorted_df.iloc[-1][0]13.931919540229886
在本文中,最主要的内容是我们将数据分为了4个不同的等级。不同的等级我们有不同的操作和可视化方法。应用这些方法我们可以加深对数据的理解与认识。当我们拿到一个新数据集时,应首先做如下操作:
- 判断数据是结构化的还是非结构化的
- 每列的数据是定量的还是定性的
- 每列处于的数据等级,是定类、定序、定距还是定比?
- 可以用什么图标可视化,条形图、饼图等。